Kỹ Thuật Tạo Dữ Liệu Phổ Biến
Trong quá trình huấn luyện mô hình ngôn ngữ, việc sử dụng dữ liệu tổng hợp (synthetic data) có thể giúp cải thiện hiệu suất và khả năng tổng quát hóa của mô hình. Dưới đây là một số kỹ thuật phổ biến để tạo dữ liệu tổng hợp
Self-Instruct Alpaca
Các mô hình ngôn ngữ lớn được "tinh chỉnh theo hướng dẫn" (instruction-tuned) đã thể hiện khả năng đáng chú ý trong việc tổng quát hóa zero-shot sang các nhiệm vụ mới. Tuy nhiên, chúng phụ thuộc nhiều vào dữ liệu hướng dẫn do con người viết, vốn thường bị hạn chế về số lượng, tính đa dạng và tính sáng tạo, do đó cản trở tính tổng quát của mô hình đã được tinh chỉnh ......
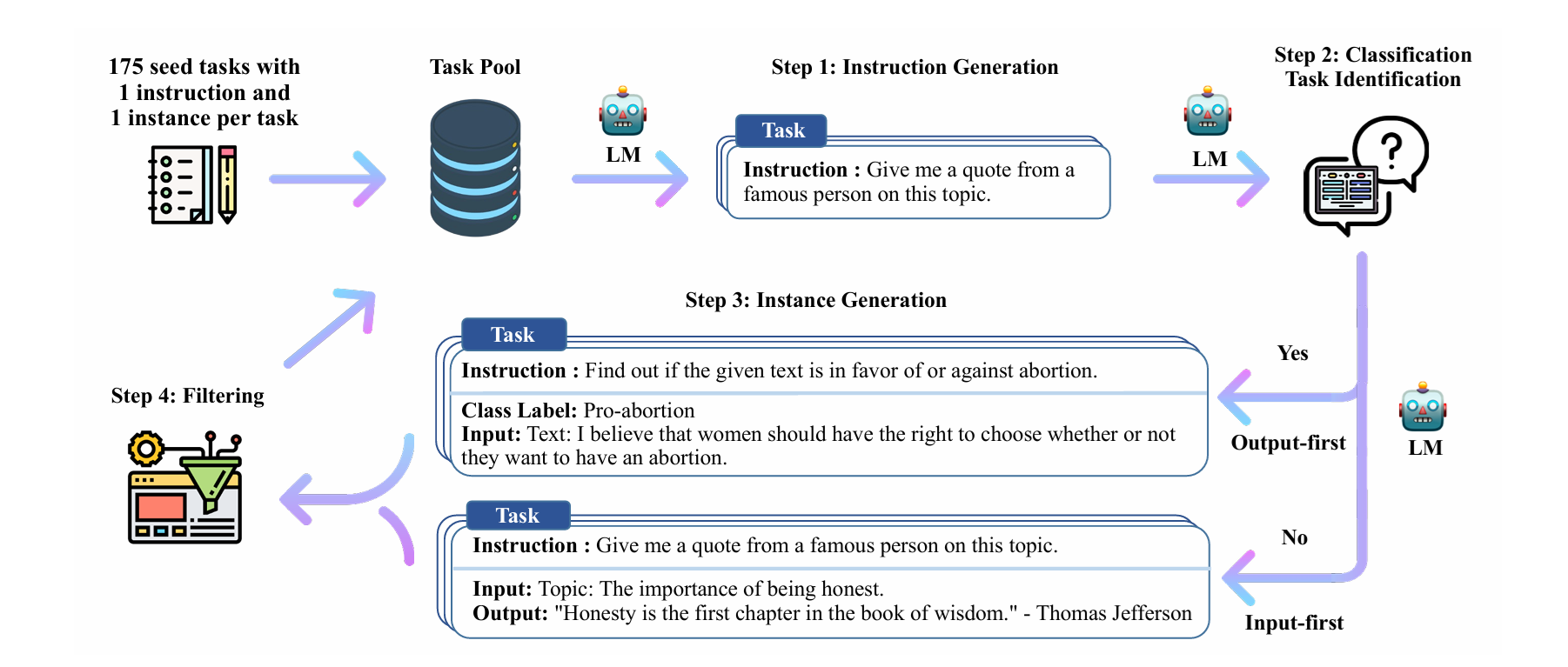 Tham khảo Self-Instruct: Aligning Language Models with Self-Generated Instructions
Tham khảo Self-Instruct: Aligning Language Models with Self-Generated Instructions
Evolutionary Algorithm
Việc huấn luyện các mô hình ngôn ngữ lớn (LLMs) bằng dữ liệu tuân thủ chỉ dẫn miền mở mang lại thành công to lớn. Tuy nhiên, việc tạo thủ công các dữ liệu chỉ dẫn như vậy rất tốn thời gian và công sức. Hơn nữa, con người có thể gặp khó khăn trong việc tạo ra các chỉ dẫn có độ phức tạp cao. Trong bài báo này, chúng tôi trình bày một phương pháp tạo ra số lượng lớn dữ liệu chỉ dẫn với các mức độ phức tạp khác nhau bằng cách sử dụng LLM thay vì con người. Bắt đầu với một bộ chỉ dẫn ban đầu, chúng tôi sử dụng Evol-Instruct được đề xuất để viết lại chúng từng bước thành các chỉ dẫn phức tạp hơn. Sau đó, chúng tôi kết hợp tất cả dữ liệu chỉ dẫn đã tạo ra để tinh chỉnh LLaMA. Chúng tôi gọi mô hình thu được là WizardLM. Cả đánh giá tự động và đánh giá của con người đều cho thấy WizardLM vượt trội hơn các mô hình cơ sở như Alpaca (được huấn luyện từ Self-Instruct) và Vicuna (được huấn luyện từ các chỉ dẫn do con người tạo ra). Kết quả thực nghiệm chứng minh rằng chất lượng của bộ dữ liệu tuân thủ chỉ dẫn được tạo ra bởi Evol-Instruct có thể cải thiện đáng kể hiệu suất của LLMs
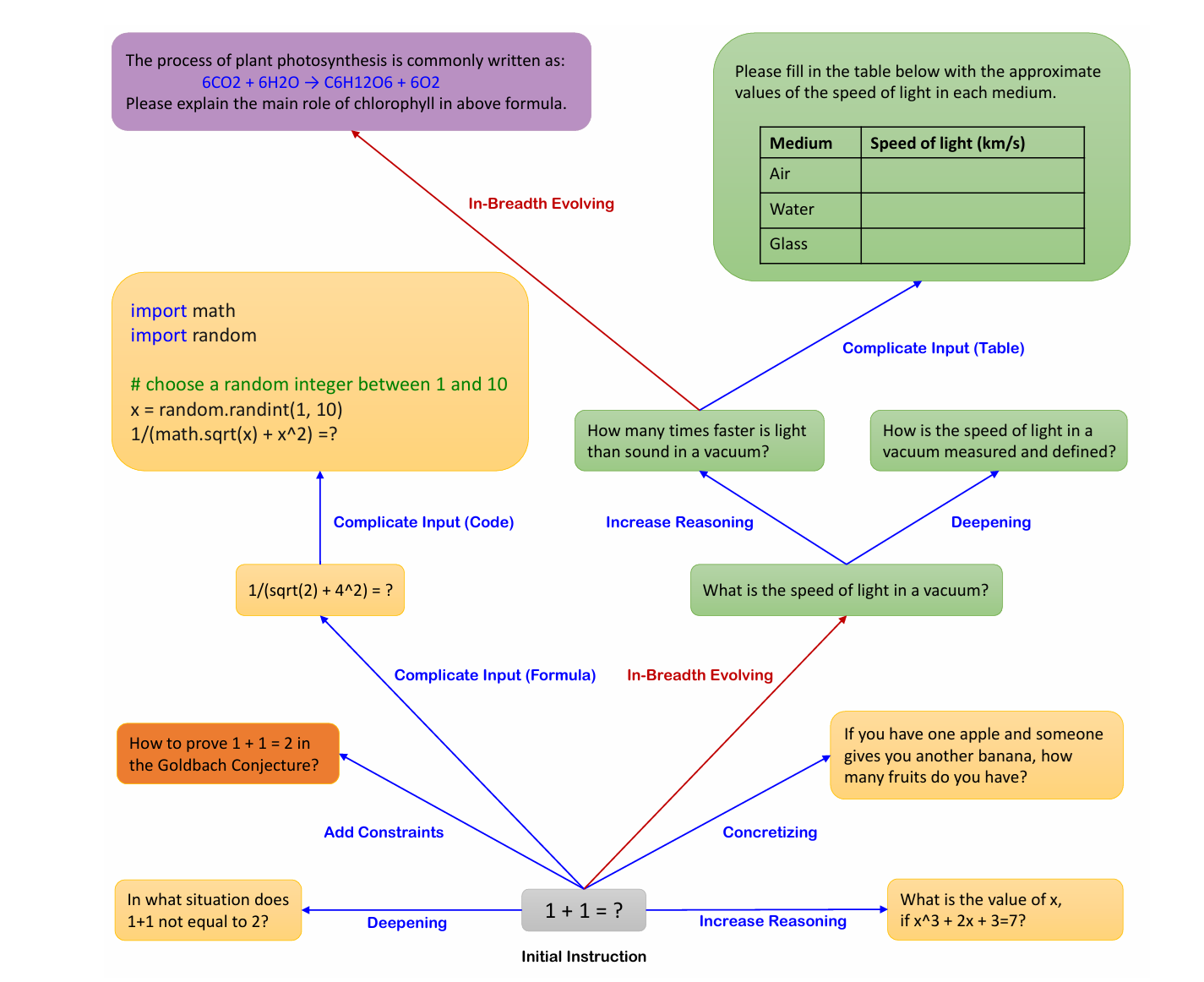
Tham khảo WizardLM: Empowering Large Pre-trained Language Models to Follow Complex Instructions
MAGPIE Algorithm
Dữ liệu hướng dẫn chất lượng cao là rất quan trọng để điều chỉnh các mô hình ngôn ngữ lớn (LLM). Mặc dù một số mô hình, chẳng hạn như Llama-3-Instruct, có trọng số mở (open weights), nhưng dữ liệu điều chỉnh của chúng vẫn được giữ kín, điều này cản trở sự dân chủ hóa AI. Chi phí lao động nhân công cao và phạm vi nhắc lệnh (prompting) được xác định trước, giới hạn đã ngăn cản các phương pháp tạo dữ liệu mã nguồn mở hiện có mở rộng quy mô một cách hiệu quả, có khả năng giới hạn sự đa dạng và chất lượng của các tập dữ liệu điều chỉnh công khai. Liệu có thể tổng hợp dữ liệu hướng dẫn chất lượng cao trên quy mô lớn bằng cách trích xuất trực tiếp từ một LLM đã được điều chỉnh không?......
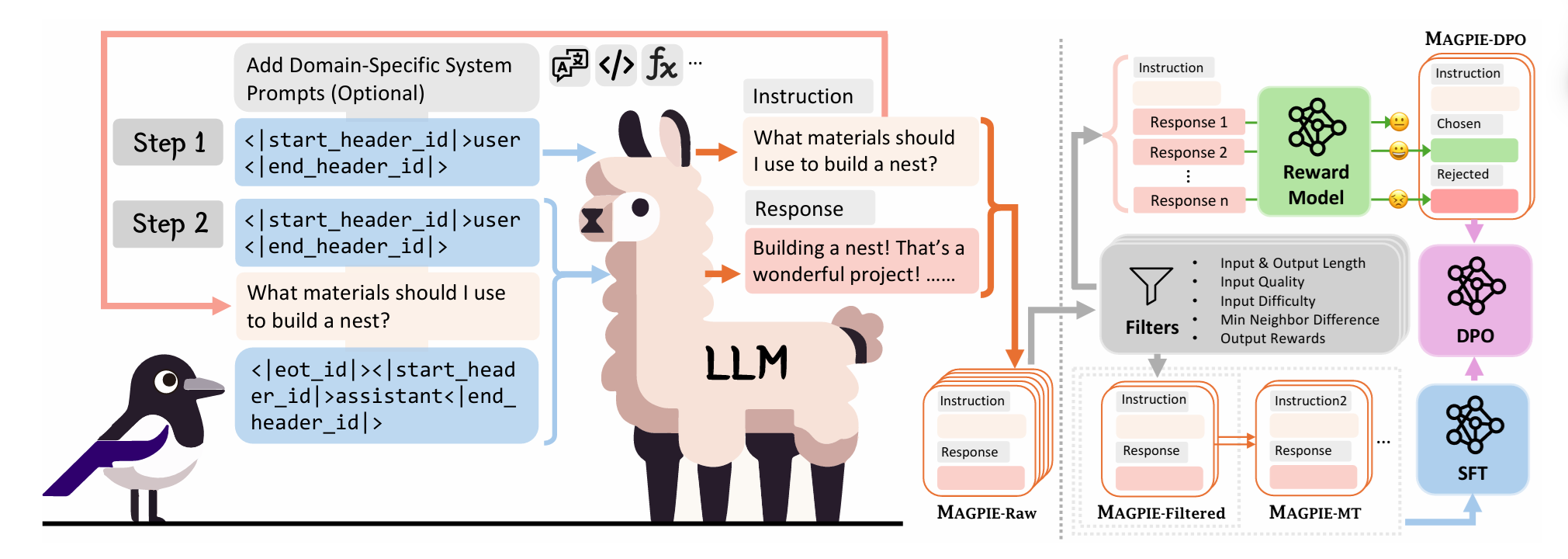
Tham khảo MAGPIE: Model-Aided Generation of Prompts for Instruction Engineering
Scaling Synthetic Data Creation with 1,000,000,000 Personas
Chúng tôi đề xuất một phương pháp tổng hợp dữ liệu mới dựa trên nhân vật (persona-driven) khai thác các góc nhìn khác nhau trong một mô hình ngôn ngữ lớn (LLM) để tạo ra dữ liệu tổng hợp đa dạng. Để khai thác triệt để phương pháp này ở quy mô lớn, chúng tôi giới thiệu Persona Hub – một bộ sưu tập 1 tỷ nhân vật đa dạng được tự động tuyển chọn từ dữ liệu web. 1 tỷ nhân vật này (tương đương ≈13% tổng dân số thế giới), hoạt động như những vật mang tri thức thế giới được phân tán, có thể khai thác gần như mọi góc nhìn được gói gọn trong LLM, từ đó tạo điều kiện cho việc tạo ra dữ liệu tổng hợp đa dạng ở quy mô lớn cho nhiều kịch bản khác nhau......
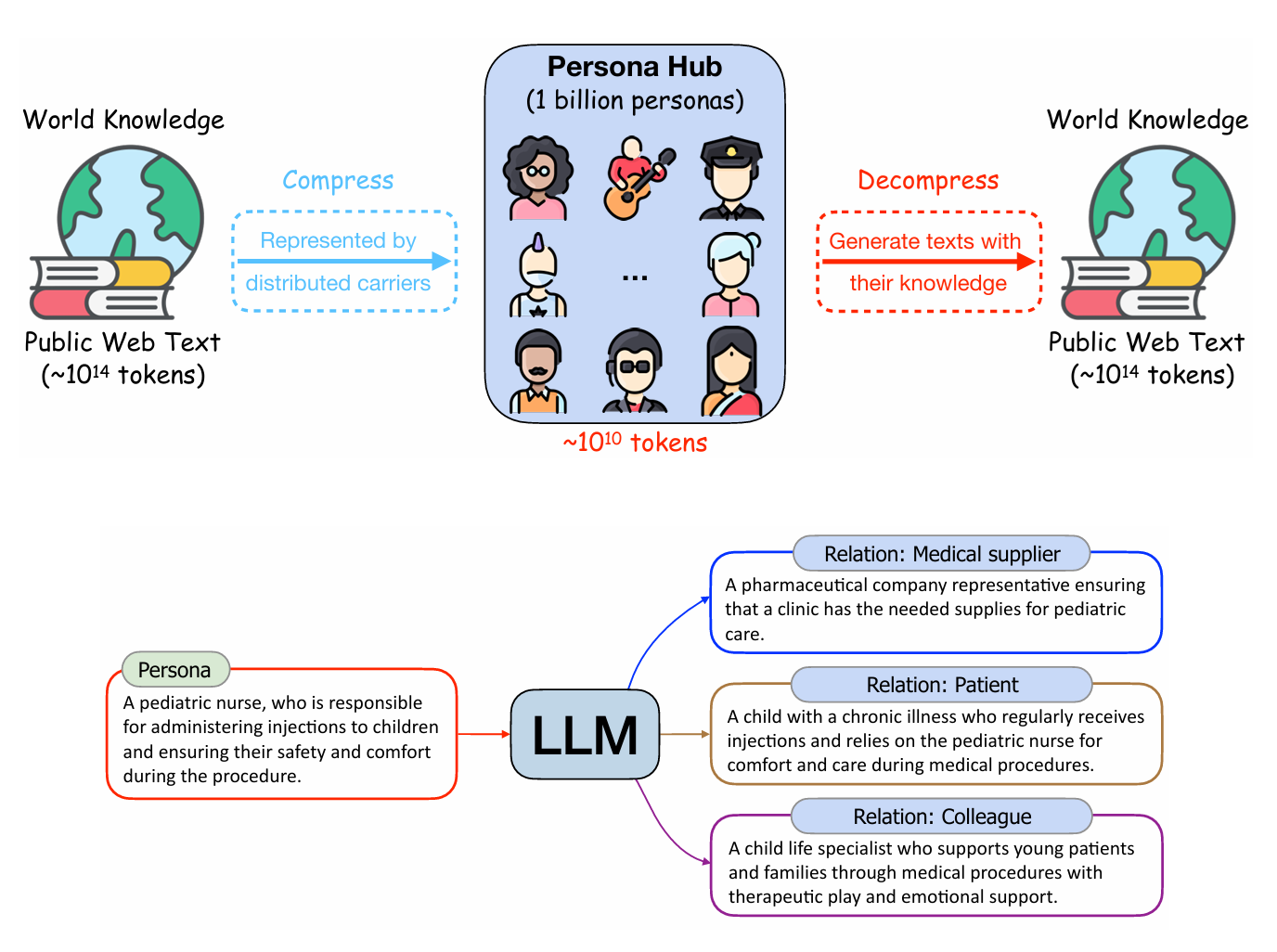
Tham khảo Scaling Synthetic Data Creation with 1,000,000,000 Personas
Mixing Data Strategies
Bộ dữ liệu tiền huấn luyện thường được thu thập từ nội dung web và thiếu sự phân chia miền (domain) vốn có. Ví dụ, các bộ dữ liệu được sử dụng rộng rãi như Common Crawl không bao gồm nhãn miền rõ ràng, trong khi việc quản lý thủ công các bộ dữ liệu được gắn nhãn như The Pile lại tốn nhiều công sức. Do đó, việc xác định hỗn hợp dữ liệu tiền huấn luyện tối ưu vẫn là một vấn đề khó khăn, mặc dù nó mang lại lợi ích đáng kể cho hiệu suất tiền huấn luyện. Để giải quyết những thách thức này, chúng tôi đề xuất CLustering-based Iterative Data Mixture Bootstrapping (CLIMB), một khuôn khổ tự động giúp khám phá, đánh giá và tinh chỉnh các hỗn hợp dữ liệu trong môi trường tiền huấn luyện.......
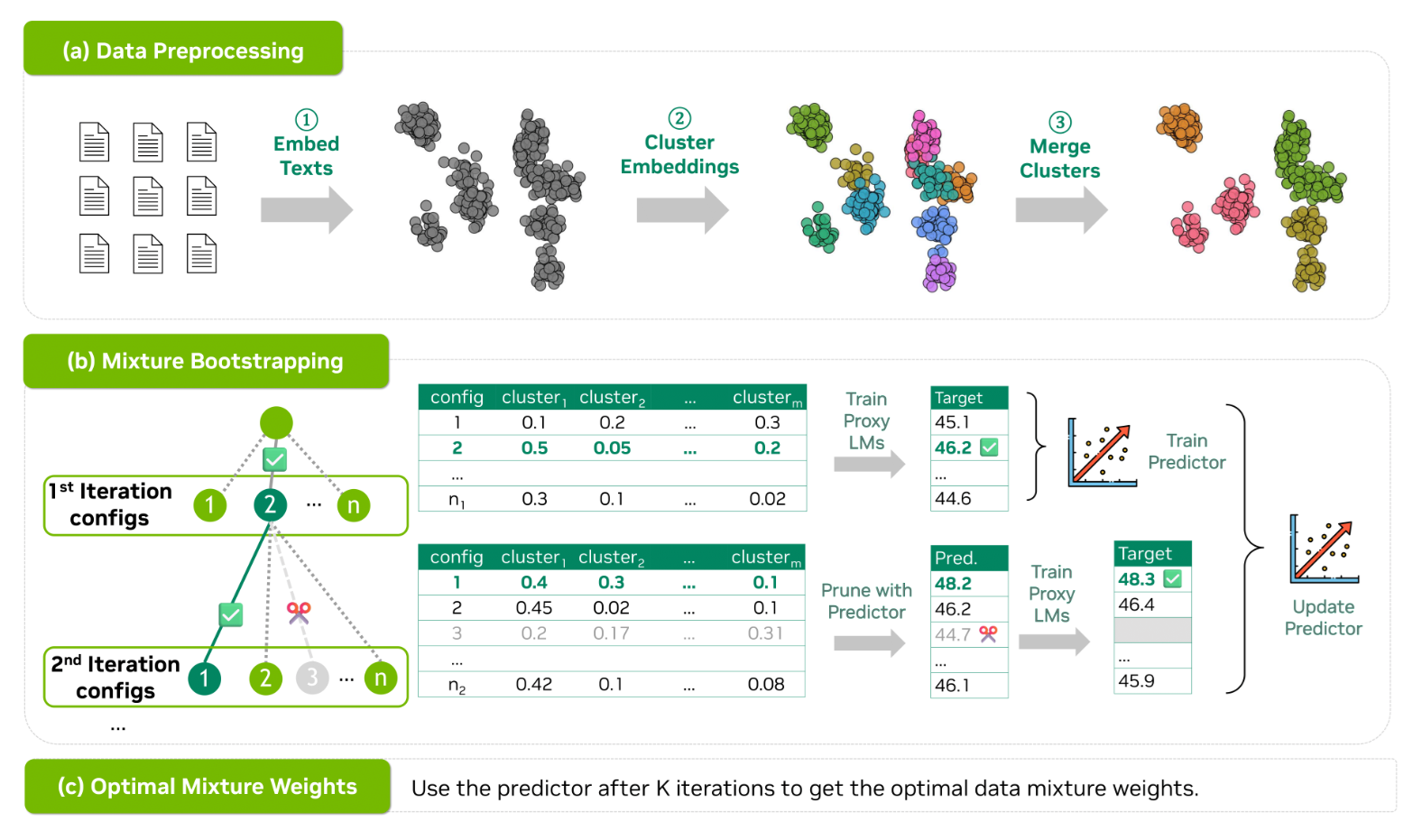
Tham khảo CLIMB: Automated Data Mixture Optimization for Language Model Pretraining
Knowledge Distillation with Synthetic Data
Chưng cất tri thức (Knowledge distillation) là kỹ thuật nén một mạng thần kinh lớn hơn, được gọi là mô hình giáo viên (teacher model), thành một mạng thần kinh nhỏ hơn, được gọi là mô hình học sinh (student model), trong khi vẫn cố gắng duy trì hiệu suất của mạng thần kinh lớn hơn càng nhiều càng tốt. Các phương pháp chưng cất tri thức hiện có chủ yếu áp dụng cho các tác vụ phân loại (classification tasks). Nhiều phương pháp trong số đó cũng yêu cầu quyền truy cập vào dữ liệu gốc được sử dụng để đào tạo mô hình giáo viên. Để giải quyết vấn đề chưng cất tri thức cho các tác vụ hồi quy (regression tasks) trong điều kiện không có dữ liệu đào tạo gốc, phương pháp hiện có sử dụng một mô hình bộ tạo (generator model) được đào tạo đối nghịch (adversarially) với mô hình học sinh để tạo dữ liệu tổng hợp đào tạo mô hình học sinh. Trong nghiên cứu này, chúng tôi đề xuất một chiến lược tạo dữ liệu tổng hợp mới, trực tiếp tối ưu hóa cho sự khác biệt lớn nhưng bị giới hạn giữa mô hình học sinh và mô hình giáo viên. Kết quả của chúng tôi trên các thử nghiệm đối chiếu cho thấy rằng chiến lược được đề xuất cho phép mô hình học sinh học tốt hơn và mô phỏng hiệu suất của mô hình giáo viên một cách sát sao hơn
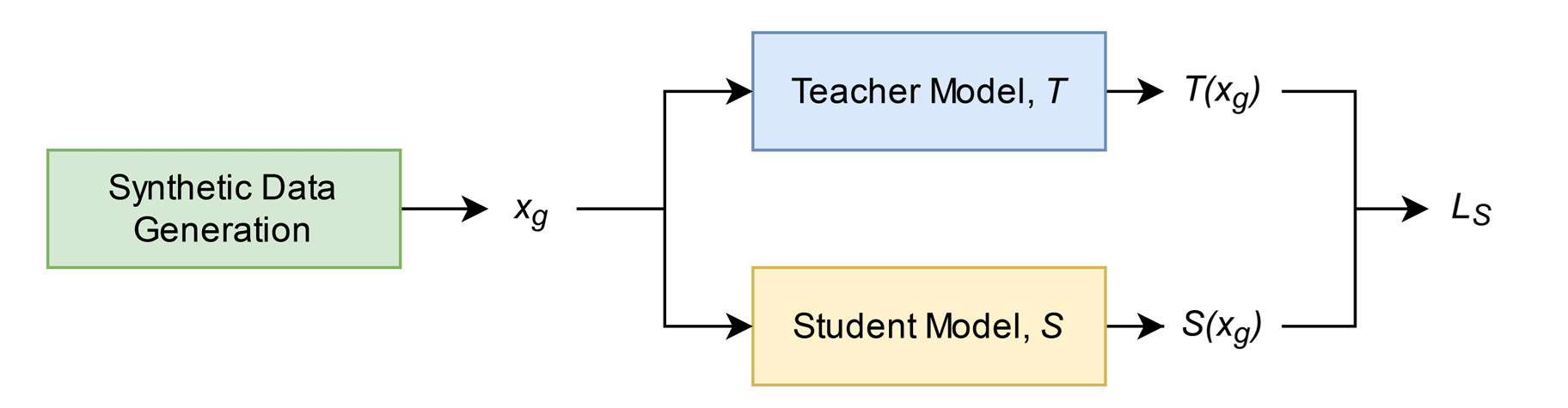 Tham khảo Synthetic data generation method for data-free knowledge
distillation in regression neural networks
Tham khảo Synthetic data generation method for data-free knowledge
distillation in regression neural networks
Xem thêm về Knowledge Distillation